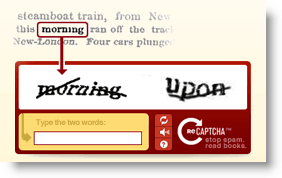
Google announced this morning they would be acquiring reCAPTCHA. This interesting acquisition makes a lot of sense. One of the original reasons (if not the original reason) for developing CAPTCHA was to ensure the person on your website or application was in fact human. BOTS would crawl through the internet and create posts and forum topics etc., to distribute SPAM and BOTS across sites. CAPTCHA would step in by displaying an image which only a human could decipher/respond to (usually), and then ask them to type in a word or several words to ensure they were HUMAN.
This is where the brilliance of this acquisition from Google comes in. As people are typing out these CAPTCHA images to register on Facebook or create a GMAIL account etc., then reCAPTCHA can display old newspapers and books which need text conversion completed. This essential process enables a free workforce to do easy (but labor intensive) work for the company that hires reCAPTCHA!
Since Google has been in the business of INDEXING the world, including old Books and Magazines, it will now have access to a FREE workforce to help translate and perfect it’s OCR technology. Like I said, brilliant.
Teaching computers to read [via Google Blogs]
Here’s a excerpt which details the shear scale of CAPTCHA and the possible workforce available for these puzzles / translation:
I thought that was rather fun thing to do, so I tested it out a bit. Works.
I wonder how long it will take before, by chance, enough people type “nigger” instead of the word to be digitalized, so that reCaptcha translates a word incorrectly…
Is there something I’m missing here?
If you get the control word wrong, they make you try again. If you get the control word right then they assume you tried your best on the 2nd word as well which is what they need. My guess is they do this several times for each word or “text” they need deciphered or translated and if several people all type the same thing, they add that into the database and move on. FREE LABOR! :)
Here’s a good one for ya – some sweat shops overseas has started a new trend… Spammers are having a hard time solving captcha’s to post their crap on forums and other websites. IE: the have to solve the captcha before they can register or post a comment on the blog etc…
So what they do is have low wage employees just sit all day and solve captcha’s so that they can continue to spam the world.
Another thing they do is take a legit site, hook into it and have legit users solve Captchas. Now the problem here is the Captchas are actually from websites which the spammers are trying to post on. Wild stuff….
This would work if the user couldn’t distinguish between the two. In 90% of the time you can.
Everytime I see one these things I always write gibberish for the OCR word.
Perhaps that’s why they probably require a few dozen??? people to solve the captcha with the same word?
It explains some of the details. If you find a better link, would really appreciate it if you could drop another comment with it! Thanks!
Using humans, you not only get a free workforce but you also get more accurate translation from paper to digital. According to the ReCaptcha website, over 200 million captcha’s are solved everyday so my guess is the OCR is going to get better and better very quickly as the OCR database grows and grows…
Many old books and newspapers out there have a lot of value but they are stored up and old libraries and “locked away” basically. By having them scanned and available through a search tool like Google, they will once again be available for the benefit of us all (and possibly the detriment..??). Either way, I appreciate your comment to the discussion.
http://www.nytimes.com/1865/08/10/news/serious-railroad-accident-norwich-steamboat-train-runs-off-track-one-passenger.html
!!! I just googled the keywords I saw. Ta-da. No hands!
Comment
Name *
Email *
Δ Save my name and email and send me emails as new comments are made to this post.

![]()
